Excel 関数でキーワードから索引に使う文字を作成する
SOFTWARE REPORT
索引に使う文字を Excel 関数で作成する
著書「Xcode 5 徹底解説」の索引を Web で掲載しようと思い、原稿作成時に整理してあった "キーワード" と "それが登場するセクション番号" のデータを Excel に取り込んで、キーワードの先頭文字から索引用の文字を Excel の関数を使って作成することにしました。
検索用文字の作成方針
今回はキーワードの先頭 1 文字を取り出して、索引用の文字として使えるように整形します。
索引用の文字は「ひらがな」を使用することにします。そのため、カタカナのキーワードだった場合に、その先頭文字列をひらがなに変換します。それと併せて今回は、たとえば『ブランチ』や『プレビュー』のように、先頭の 1 文字に「濁点」(゛)や「半濁点」(゜)が入ったキーワードの場合は、それを含まない『フォント』と同じ【ふ】を、索引用の文字として当てることにします。
それらを踏まえ、索引用の文字列を生成する計算式と、その計算式を組み立てる上でひつような『ひらがなをカタカナに変換する方法』や『濁点や半濁点を取り除く方法』を紹介して行きます。
組みあがった計算式
まず、結論から紹介すると、今回の目的を実現するにあたって、次のような計算式が組みあがりました。
=CHAR(CODE(JIS(LEFT(ASC(IF(AND(CODE(A2)>=9249, CODE(A2)<=9339), CHAR(CODE(A2)+256), A2)))))-256)
この計算式を、先頭の 1 文字がひらがなまたはカタカナのセルに対して使用すると、索引用の文字を取得できます。
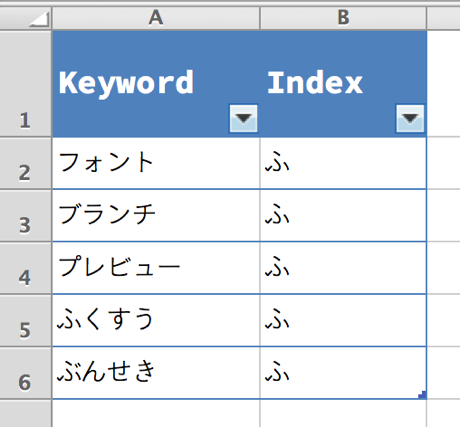
この例では "B 列" にこの計算式を設定して、"A 列" の内容から索引用の文字を取得しています。
たくさんの関数を使っていて複雑なので、これらがどのような意味で構成されているのかを、以下で説明して行きます。
索引に使う文字を抽出する関数の組み立て方
それでは、上記で紹介した関数をどのように組み立てたかを、順を追って説明します。
Step.1 : 濁点や半濁点を取り除いて、索引で使う文字を完成させる
まずは、今回の関数でいちばん肝要な、濁点や半濁点を含むひらがなを取り除いて、索引で使う文字を完成させるところから考えます。
もしこれを力技で実現するなら「『ぷ』や『ぶ』が見つかった場合は『ふ』に変換する」という処理を、『が』や『ぎ』や『ぱ』や…、というように存在するすべての文字に対して行えば良いのですけど、これを Excel の関数だけで実現するのは難しそうです。
全角カタカナを半角カタカナに変換し、濁音や半濁音を取り除く
Excel に用意されている関数で便利そうなものがないか調べてみたところ、ASC関数が使えそうなことが分かりました。
この ASC 関数は「引数に渡された文字列を、可能な限り ASCII 文字列で表現可能な文字列に変換する」機能を持っています。ASCII 文字列というのは、昔 8 bit で 1 文字を表していた頃に同じみな形式で、いわゆる半角文字で構成された文字列になります。
ひらがなの場合は全角文字しかないので ASC 関数を通しても何も起こりませんが、カタカナの場合は半角カタカナというものが存在するので、ASC 関数を通すことで、全角カタカナが半角カタカナに置き換わります。
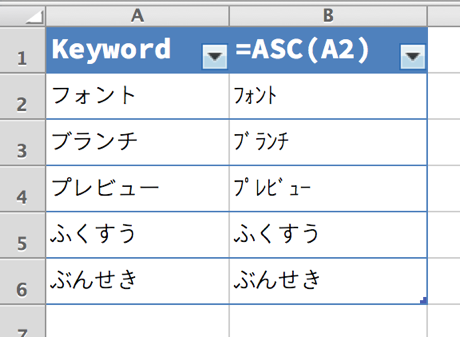
この半角カタカナの特徴として、濁音や半濁音も 1 文字として表現されるというのがあります。
つまり、ASC 関数で半角カタカナにして、先頭の 1 文字を取得すれば、濁点や半濁点を除いた 1 文字が取得できることになります。先頭 1 文字を抽出するには、左から指定した文字数だけ取り出すLEFT関数を使います。
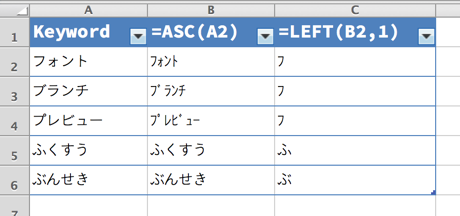
こうすることで、カタカナで始まるキーワードに限っては、濁点や半濁点の有無にかかわらず、それらのつかない先頭文字が半角カタカナで取得できました。ひらがなについては変化なしです。
半角カタカナを全角カタカナに変換する
カタカナは変換できましたが、半角カタカナのままだと不格好なので、これを全角文字に戻します。
それにはJIS関数を使用します。この関数に文字列を渡すことで、JIS 文字列として最適な文字列に変換されます。ここでは、半角カタカナが全角カタカナに変換されます。
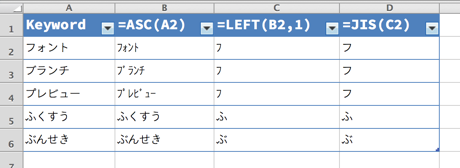
このようにすることで、カタカナに限っては、濁点や半濁点を抜いた文字に変換できました。
これらの関数をひとつにまとめると、次の通りになります。
=JIS(LEFT(ASC(A2),1))
この関数で「カタカナの文字列から先頭の 1 字を取り出して、濁点や半濁点を取り除く」という処理を実現できます。
Step.2 : ひらがな 1 文字をカタカナに変換する
先ほどの処理では、カタカナは期待どおりに変換されるものの、ひらがなが変換されない問題があります。
これについては「文字がカタカナであれば変換できる」ところに注目して、「先頭の文字が『ひらがな』だった場合に、それを『カタカナ』に変換する」という方法で解決できます。
JIS コードを編集して、ひらがなをカタカナに変換する
文字を処理するときには「文字コード」を使うことが多いですが、Excel ではCODE関数を使うと、文字を文字コード(JIS コード)に変換できます。
ひらがなやカタカナ周りの JIS コード表を調べてみると、一般的に使われる文字であれば 、ひらがなは 9249 〜 9339 の範囲に、カタカナは 9505 〜 9595 の範囲に、同じ順番で並べられているのが確認できます。ここから、ひらがなの文字とそれが対応するカタカナの文字とでは、文字コードがちょうど 256 だけ、ズレていることが分かります。
そのため、ひらがなの文字の JIS コードに 256 を足してあげれば、カタカナに変換できます。ちなみに、文字コードを文字に戻すにはCHAR関数が使えます。
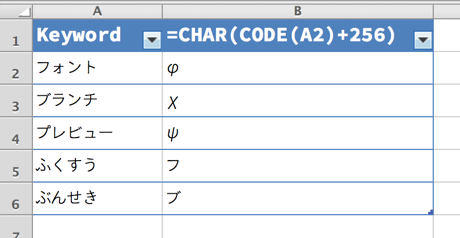
こうすることで、ひらがなに限って、カタカナに変換されました。変換後の文字が 1 文字だけになっているのは、CODE 関数が「先頭 1 文字の文字コードを返す」ためです。
既にカタカナの場合は編集しないようにして、文字化けを防ぐ
なお、カタカナをそのまま処理してしまうとぜんぜん関係ない文字に変化してしまうので、カタカナだった場合は無視する必要があります。
そのために、次のコードを使用します。
=IF(AND(CODE(A2) >= 9249, CODE(A2) <= 9339), CHAR(CODE(A2)+256), A2)
ここではIF関数を使って、条件に応じて処理の切り替えを行っています。
IF 関数内の最初の "AND(CODE(A2) >= 9249, CODE(A2) <= 9339)" で、セル "A2" の先頭文字の JIS コードが 9249 から 9339 の範囲内にあるかを判定しています。これで、最初の 1 文字がひらがなであるか、そうでないかが判定できます。
そして、ひらがなだった場合は、セル "A2" に対して先ほど紹介したカタカナへの変換関数 "CHAR(CODE(A2)+256)" を実行した結果を取得します。ひらがなではなかった場合は、"A2" セルを変換せずにそのまま取得しています。
このようにすることで、先頭文字をカタカナに揃えることができました。

これを、最初に紹介した「カタカナの文字列から先頭の 1 字を取り出して、濁点や半濁点を取り除く」関数に渡すことで、ひらがなのキーワードも含めて、濁点や半濁点を取り除いた先頭の 1 文字を取得できます。

これで「索引で使う文字を作成する」という目的はおおよそ達成しましたが、今回はひらがなの文字を使いたかったので、最後にこのカタカナをひらがなに変換することにします。
Step.3 : カタカナ 1 文字をひらがなに変換する
カタカナ 1 文字をひらがなに変換するのは、これまでの方法を使って簡単にできます。
=CHAR(CODE(C2)-256))
ひらがなの JIS コードは、カタカナの JIS コードよりも、ちょうど 256 だけ少ない値なので、カタカナを CODE 関数で JIS コードに変換して、そこから 256 を引いて CHAR 関数で文字に戻せば完成です。
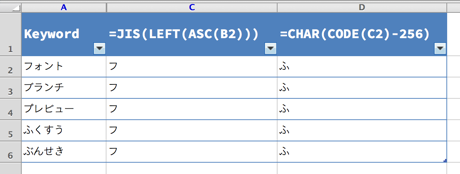
これで、冒頭で紹介した、キーワードに対応する索引用の 1 文字を取得することができました。
ここで紹介した方法は「ひらがな」または「カタカナ」だけにしか対応していないので、漢字のキーワードも扱う場合は、別のセルに読み仮名を入力するなどして対応するようにします。または Excel で直接入力した漢字に限られますが、PHONETIC関数を使うと振り仮名が取得できるので、可能であればそれを使って漢字を自動的に仮名に変換するのも良いかもしれません。